异常值过滤器
功能概述
异常值过滤器指在栅格数据处理中,检测并处理(替换/剔除/标记)那些与邻域或总体统计显著偏离的像元。目的不是盲目平滑,而是去除测量误差、传感器坏点、单点干扰或拼接断层等“异常”值,同时尽量保持真实边界与地物结构。
异常值过滤通常由两步组成:
- 检测:用统计/局部/时间等规则判定哪些像元为异常。
- 处理:对检测到的异常像元进行替换、插值、掩盖或标记。
适用场景
- 遥感影像: 单像元坏点、传感器条带、拼接缝、云影残留(结合云掩膜)。
- DEM: 孤立高峰/洼陷校正、剔除测高误差点(注意保留真实地形特征)。
- 多时相监测: 去掉临时异常观测(如云影、太阳闪烁)以得到稳健时序。
- 分类栅格: 去斑(用众数/多数滤波而不是均值);
- 环境监测: 传感器突变点、测站错误记录的空间表现剔除。
参数介绍
| 参数名称 | 参数描述 | 补充说明 |
|---|---|---|
| 输入栅格文件 | 待进行异常值检测与过滤处理的栅格数据集 | 建议确保输入数据具有正确的空间参考和坐标系,以保证结果的空间一致性 |
| 滤波器大小奇数 | 定义滤波窗口的行列数,必须为奇数以确保存在唯一的中心像元 | 常见取值如 3×3、5×5、7×7;窗口越大平滑效果越强,但细节可能丢失 |
| 异常值检测方法 | 用于识别栅格数据中异常值的判别方法 | 支持标准差法、四分位距法;方法选择应结合数据分布特性 |
| 异常值替换方法 | 对检测出的异常值进行替换时所采用的方法 | 可选方式包括:最近邻插值、线性插值、三次卷积、邻域均值、邻域中位数等 |
| 处理边界的模式 | 控制卷积计算中如何处理超出栅格边界的邻域像元值 | 常见模式:常数填充、边界反射、边界镜像、最近边界值、边界环绕等。不同模式对边缘像元的处理结果差异显著 |
| 阈值 | 判断像元是否被判定为异常值的关键参数 | 阈值大小直接决定异常检测的灵敏度,应结合数据分布和分析目标合理设置 |
| 四分位距法的系数 | 当采用四分位距法时,用于调整异常值识别范围的系数 | 通常设为 1.5 或 3;数值越大,识别出的异常值越少 |
| 输出路径 | 存放结果栅格的目标目录(建议使用绝对路径以避免歧义) | 建议使用绝对路径,确保目录存在且具有写入权限;路径避免使用中文及特殊字符以提高跨平台兼容性 |
| 输出文件名 | 结果栅格文件的完整名称(含扩展名) | 扩展名将决定输出文件格式,如 .tif 生成 GeoTIFF 文件,.img 生成 ERDAS IMG 文件 |
操作步骤
-
启动工具
打开【空间分析工具】工具箱→ 双击启动【异常值过滤器】工具窗格。
-
输入栅格文件
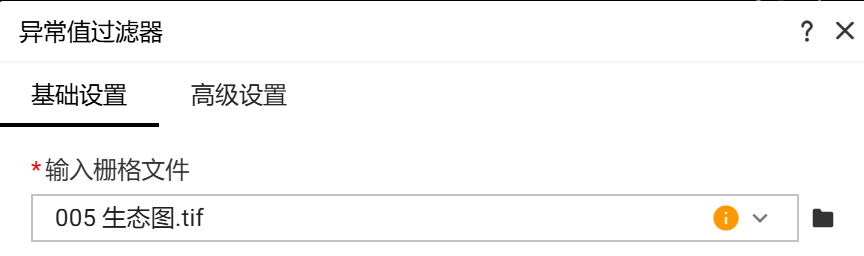
- 【输入栅格文件】:输入 "005生态图.tif"。
-
滤波器大小以及异常值方法设置

-
【滤波器大小奇数】:输入 "3"
-
【异常值检测方法】:选择"标准差法"
-
【异常值替换方法】:选择"最近邻插值"
异常值检测方法:
标准差法(Z-score):用均值和标准差衡量像元与总体/局部分布偏离程度,偏离超过 k 倍标准差视为异常。
四分位距法(IQR):用第 1 四分位数(Q1)和第 3 四分位数(Q3)计算 IQR = Q3 − Q1,超出 Q1 − k·IQR或 Q3 + k·IQR的像元视为异常(k 常取 1.5)。
标准差法
- 优点:简单、易实现(只需均值和 std);适合近似正态分布数据。
- 缺点:对极端值敏感——异常值会拉高均值和标准差,从而降低自身或其它极值的检测能力;对偏斜分布也不理想。
四分位距法(IQR)
- 优点:基于中位数及分位数,更鲁棒于极端值和偏斜分布;在含异常的数据中通常更可靠。
- 缺点:对非常稀少的数据样本或非常小邻域(样本量小)时,分位数估计不稳定;无法直接给出“偏差倍数”的直观数值(但能给出上下界)。
异常值替换方法:
最近邻插值:
原理:取目标像元最近的一个非异常(或已知)像元的值作为替换值。空间上基于最短距离或最近格网中心决定采样点。
算法要点
- 只使用单个最近像元的原始值,不做加权平均。
- 对分类数据保真(不会产生新类别值)。
优点
- 不产生新的数值(对分类/离散数据安全)。
- 计算速度快、实现简单。
- 保持原始数据的整数/类别特性。
缺点
- 结果块状感强,边缘/过渡区域可能不平滑。
- 对连续变量可能产生阶梯状伪影。
适用场景
- 分类栅格(土地利用、土地覆盖)。
- 当必须保留原始类别或离散编码时(例如编号类属性)。
线性插值
原理:在二维上采用双线性插值:用包含目标点的四个邻像元的值,按横纵方向的相对距离加权平均得到插值结果。
优点
- 平滑、连续,能消除“阶梯效应”。
- 计算代价低于三次卷积,结果比最近邻细腻。
缺点
- 会产生原始数据中不存在的中间数值(不适合分类数据)。
- 相比三次卷积细节恢复能力弱,边缘会有轻微模糊。
- 对极端值不鲁棒(异常值会影响结果)。
适用场景
- 连续型栅格(反射率、高程、温度等)。
- 填补孤点或小区域缺失,且可接受平滑/新值。
三次卷积
原理:用目标像元周围更大邻域(通常 4×4 共 16 个像元)按三次多项式核加权插值,比双线性使用更多样本与更平滑的权重函数
优点
- 较双线性保留更多影像细节与锐度,过渡更自然。
- 视觉上常比双线性更“清晰”。
缺点
- 计算成本高于双线性与最近邻。
- 可能出现“振铃/超调”现象(插值值超出邻域值范围),对一些业务(如绝对范围敏感的物理量)需谨慎。
- 同样不适合分类数据。
适用场景
- 连续数据,且希望在插值时尽量保留纹理细节(遥感可见光、影像可视化、DEM 轻微放大等)。
- 影像重采样以供展示或进一步连续分析。
邻域均值
原理:在给定窗口(如 3×3、5×5)内,对所有(或忽略 NaN 的)像元取算术平均,用平均值替换异常像元。
优点
- 简单、稳定,能有效降低随机噪声与孤立异常。
- 实现成本低。
缺点
- 会模糊边缘与小尺度细节(方差下降)。
- 对分类栅格不适用(会产生不合规的中间值)。
- 对异常值并不鲁棒(单个极端值会拉动平均)。
适用场景
-
需要轻度平滑连续型数据(噪声小、但需去掉孤立异常)。
-
作为初步替换策略,再用其它方法修正边界。
邻域中位数
原理:在窗口内对非 NaN 值排序,取中位数作为替换值。
优点
- 对孤立极端值(椒盐噪声)非常鲁棒,不受极端值拉动。
- 相比均值更能保持边缘(边界被平滑但不至于严重模糊)。
- 简单、易实现。
缺点
- 比均值计算稍昂贵。
- 对大斑块的异常不一定有效(中位数受群体影响)。
- 对离散类别数据的意义有限(对类别编码可产生“中间数值”,通常更推荐众数/多数滤波处理分类数据)。
适用场景
- 去除单点噪声或小斑点(遥感影像、DEM 的孤立异常)。
- 保持边界完整性同时去噪的情形。
-
-
处理边界模式以及阈值设置

-
【处理边界模式】:选择"边界反射"
-
【阈值】:输入"2"
-
【四分位距法的系数】:输入"1.5"
四分位距法
四分位距法是一种基于统计分布的异常值检测方法,利用数据的 Q1(第一四分位数,25%分位点) 和 Q3(第三四分位数,75%分位点) 来衡量数据的离散程度。
- 四分位距(IQR):
IQR = Q3 - Q1
- 异常值判定区间:
下界=Q1−k×IQR
上界=Q3+k×IQR
其中 k 就是所谓的系数。
系数的作用:
- 系数 k 决定了对“异常值”判定的严格程度。
- 系数越小 → 判定越严格,更多数据点会被标记为异常;
- 系数越大 → 判定越宽松,只有极端偏离的点才会被认为是异常。
系数取值:
k = 1.5
- 最常用的经验值。
- 适用于一般统计分析与数据清洗。
- 判定为“轻度异常值”。
k = 3.0
- 判定更宽松,仅标记严重偏离的点。
- 用于识别“极端异常值”。
自定义系数(k 可调)
- 在遥感影像和栅格分析中,可以根据数据噪声水平和研究目标自行调整
-
-
指定输出位置

- 【输出路径】:输出至 "用户空间/工具箱/空间分析工具"
- 【输出文件名】:输入 "Outlierfilt.tif"
-
执行生成
- 点击窗格底部的 【运行】 按钮 → 等待任务列表提示"工具执行成功"
注意事项
- 区分数据类型:分类栅格不能用均值替换,应用众数/多数或斑块合并策略。
- 谨慎选择邻域与阈值:邻域过大或阈值过松会把真实特征当异常删除;过小或阈值过严格则过滤效果弱。
- 对 NoData 的处理策略要一致:计算局部统计时建议忽略 NoData;替换完毕再处理残余 NoData(填充或保持)。
- 记录所有参数:便于复现:邻域大小、阈值类型与系数、替换方法、NoData 策略、边界填充方式。