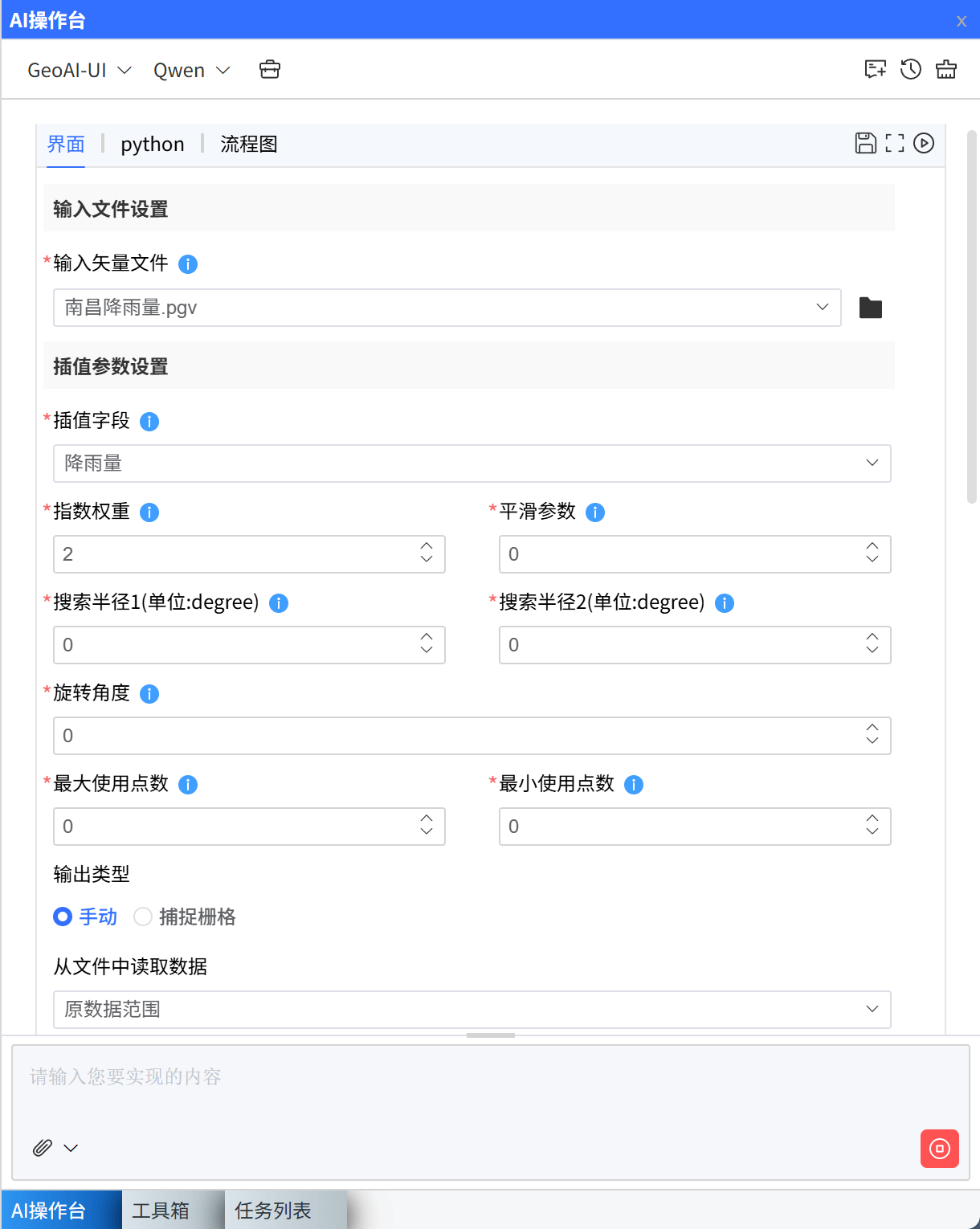
空间分析工具箱
AI 计算
要实现“AI 通过自然语言理解用户目的 → 自动组合空间分析工具链执行”,核心在于构建一个具备空间语义理解能力的 AI 工具调用系统,它能:
- 理解用户的意图(例如“找出洪水高风险区”)
- 自动选择合适的 GIS 工具(如重分类、叠加分析、缓冲区)
- 确定执行顺序、填入参数,完成整个分析流程
现在支持两种模式Code 模式 和 UI模式,Code 模式 支持生成一段python代码,用来构建用户需求并计算;UI 模式支持 调用工具箱中的UI。
Code 模式
Code 模式 支持生成一段python代码,用来构建用户需求并计算,在昕图内已经有实现该需求的代码时,他会调用已有的成熟的代码;没有时,LLM模型会现编一段代码,此时,稳定性会削弱,代码可能无法运行,需要用户反复调试。

UI 模式
UI 模式支持生成一段python代码,此时,大多用来调用已有的工具箱,并根据用户数据的特征来填参数,并将界面表现在当前对话窗口中,用户可在界面中调整参数,点击右上角的运行按钮,在此运行。
计算框架
昕图XinGEO的设计目标就是一个GIS数据处理的平台,以服务器强大的多核计算能力为依托,提供GIS数据计算,更深入来说是一个模型计算平台,耦合GIS和专业模型,集成气象、生态、环境等领域专业模型,可进行高性能计算。
在开发CRGIS时,我们采用Numpy和Geopandas进行gis计算,但在使用过程中,发现先,Numpy对栅格数据进行处理,当栅格数据较大时导致内存溢出;且numpy运行过程无法并行,无法发挥服务器多核和集群的优势。
因此我们在XinGEO开发时,采用了dask,XArray、rioxarray替代numpy实现栅格大数据的运行处理。理论上,凭他可以计算非常大的栅格数据,比如中国30m分辨率的地形数据,可以直接进行计算,且是并行的。
多进程运行对比
在Numpy和dask的选择上,我们进行了多次对比,发现使用DASK编程,计算效率远高于Numpy。
Dask是一个并行计算库,用于在单个计算机或集群上扩展Python代码。它可以用来处理大规模数据计算,并能够与许多科学计算和数据分析库(如NumPy、Pandas和Scikit-Learn)无缝集成。Dask的核心组件包括Dask数组、Dask数据框和Dask延迟,这些组件可以帮助用户有效地分配和管理计算任务。
from dask.distributed import Client, WorkerPlugin
client = Client(threads_per_worker=1, n_workers=8)
通过client = Client(threads_per_worker=1, n_workers=8)来启动多核,其中threads_per_worker为线程数,n_workers为进程数。
对于计算密集型的,利用集群来计算是合适的。
import dask.array as da
import numpy as np
from dask.distributed import Client
def main():
# 创建一个随机的 NumPy 数组
np_array = np.random.random((2000, 2000))
# 将 NumPy 数组转换为 Dask 数组
dask_array = da.from_array(np_array, chunks=(500, 500))
# 定义一个用于块处理的函数
def process_block(block):
# 在这个例子中,我们简单地对每个块取平方
return block ** 2
# 使用 map_blocks 对每个块进行处理
result = dask_array.map_blocks(process_block)
client = Client(threads_per_worker=1, n_workers=1) # 根据 CPU 核心数增加 worker 数量
import time
start_time=time.time()
# 计算结果并收集
computed_result = result.compute()
print(f'time:{time.time()-start_time}' )
client.close()
# 打印结果的形状
print(computed_result.shape)
if __name__ == '__main__':
main()
上面的例子不开启集群,运行时间为0.535s左右。
| 多核开启情况 | 低计算量 | 高计算量 |
|---|---|---|
| 不开启 | 0.0189s | 13.449s |
| n_workers=1 | 0.2549 | 4.867s |
| n_workers=4 | 0.1905 | 1.587s |
| n_workers=8 | 0.182 | 1.377s |
如果在分布式集群环境下,只运行多线程compute(scheduler='threads'),运行时间为0.02268。
工具箱分组
矢量工具箱
矢量工具箱是一组专为点、线、面要素(Feature)设计的几何处理与属性管理工具。它旨在解决矢量数据在采集、生产及入库过程中的几何拓扑与数据结构问题。
核心功能涵盖:
- 矢量数据:提供数据数据的创建、裁剪、合并等数据操作
- 字段:提供字段计算、变换字段、添加特定字段等字段操作。
- 要素计算:提供要素相关的计算
- 要素处理:提供要素的拆分、构建、修整、分割、选择等操作
- 要素转换:实现点、线、面之间的相互转化(如面转线、折点转点)。
- 属性处理:提供矢量数据属性表的相关操作
栅格工具箱
栅格工具箱是一组处理栅格数据的工具。
主要包括:
- 栅格数据:提供创建栅格、镶嵌
- 插值为栅格:提供矢量插值为栅格数据功能
- 栅格计算:提供栅格计算器,为地图代数在昕图中实现
- 栅格处理:提供栅格数据一些处理功能
- 栅格属性:提供栅格数据属性表的操作,此为
待开发状态。
数据管理工具箱
数据管理工具箱负责构建空间数据的底层逻辑,确保数据在不同系统与标准间能够无缝流通。它是所有空间分析任务的前置保障。
核心功能涵盖:
- 投影:提供数据的坐标系定义和转换功能
- 数据转换:提供其他格式转为昕图支持编辑的矢量和栅格数据功能,提供昕图内的数据转为其他格式的功能,提供栅格和矢量的相互转换功能
- 数据下载:集成全球/全国范围一些公用数据的快速获取。
分析工具箱
分析工具箱主要基于矢量数据执行经典的空间叠加与提取运算,用于解决“在哪里”以及“它们如何重叠”的逻辑问题。
核心功能涵盖:
- 叠加分析:相交(Intersect)、联合(Union)、擦除(Erase)及空间连接(Spatial Join)。
- 提取分析:裁剪(Clip)、筛选(Select)及按属性分割。
- 邻域分析:构建平面或测地线缓冲区(Buffer)。
空间分析工具箱
Spatial Analyst 工具箱为栅格(基于像元的)数据和要素(矢量)数据提供一组空间分析和建模工具。
核心功能涵盖:
- 局部分析:基于多层栅格的逐像元统计与逻辑判断。
- 邻域分析:包括焦点统计(Focal Statistics)与块统计(Block Statistics)。
- 像素处理:提供卷积滤波、锐化、模糊及阈值化等图像增强手段。
栅格保存一般约定
无论是何种工具,该工具如果输出结果为栅格数据时,则具有栅格通用输出设置。该设置用于定义输出栅格的空间结构、数据类型及存储方式,并对最终结果具有全局约束作用。无论工具的内部计算逻辑如何,输出结果均受以下设置项控制。
输出类型
在保存栅格数据时,可以手动设置栅格保存参数,也可以使用捕捉栅格,来设置与参考栅格一模一样的参数。
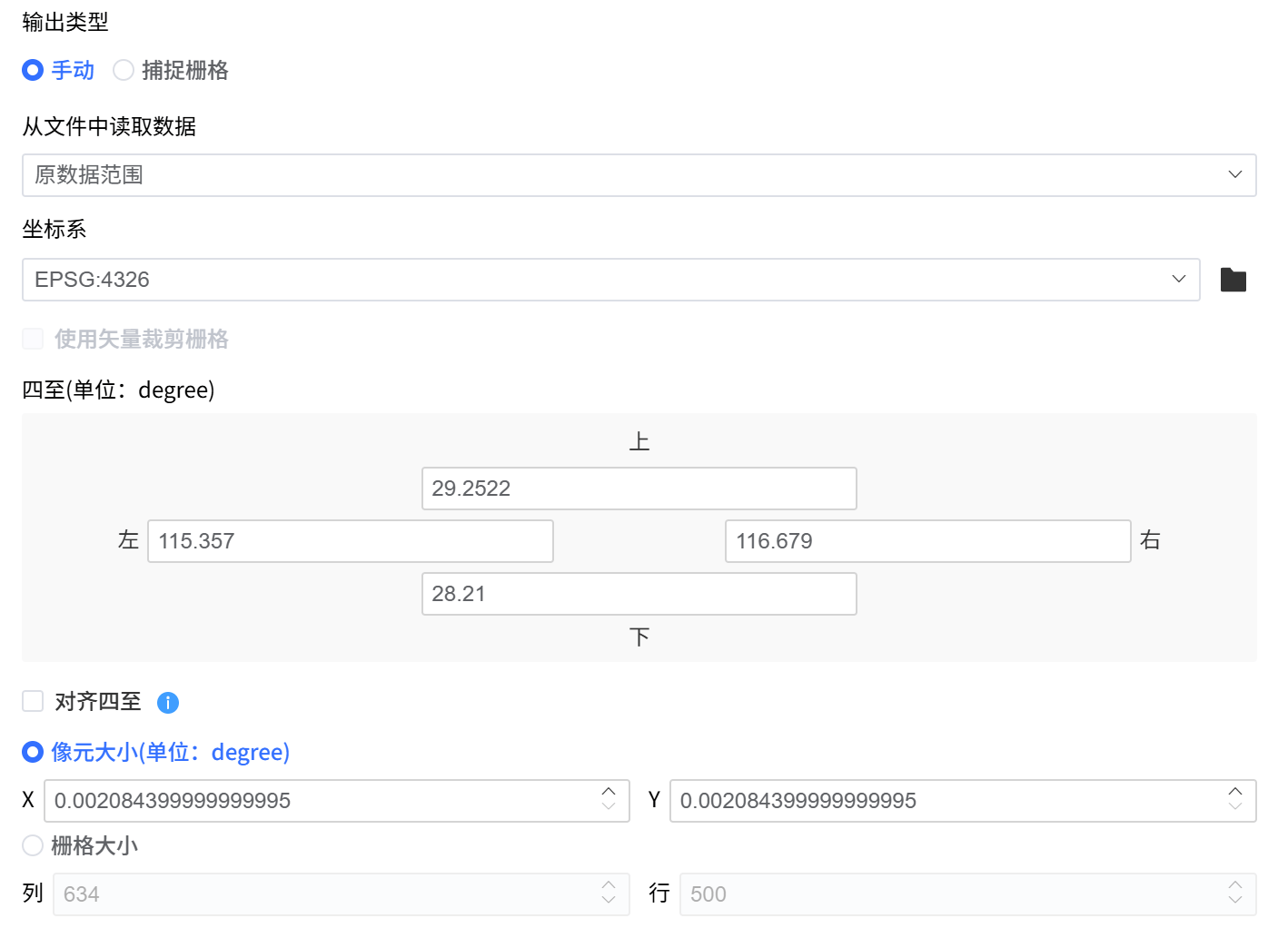
手动输入
在“手动输入”模式下,输出栅格的所有关键空间与数值参数均由用户显式指定。
1.可配置参数
-
空间参考与范围
- 输出坐标系
- 栅格空间四至(Extent)
-
网格与数值结构
- 像元大小
- 栅格行列数(栅格大小)
- 像元数据类型
- NoData 值
- 压缩类型
-
输出格式
- 栅格文件格式
2.范围与分辨率协调规则
当输出范围与网格参数存在不完全匹配时,系统提供以下两种处理方式:
- 保持输出范围 以指定的输出四至为最终范围,系统将通过自动微调像元大小或栅格行列数,使输出结果严格覆盖该范围。
- 保持像元与栅格大小 以指定的像元大小和栅格行列数为准,系统将相应调整输出四至范围。
使用矢量数据
当选择矢量数据作为参考时,系统可直接读取矢量数据的空间信息,用于辅助定义输出范围和裁剪规则。
1.自动读取内容
选取任意矢量数据后,系统将自动读取并填充以下参数:
- 坐标系
- 空间四至范围
2.基于矢量的裁剪设置
工具支持使用矢量几何对输出栅格进行裁剪:
- 保持裁剪范围 启用后,系统将自动调整像元大小与栅格大小,确保输出结果严格保持指定的裁剪范围。
- 使用输入要素裁剪几何
启用后,可选择裁剪类型:
- 内部裁剪 将位于矢量几何内部的栅格区域裁剪掉,仅保留外部区域。输出四至由系统自动计算。
- 外部裁剪 以矢量几何内部区域作为最终输出范围,裁剪掉位于矢量几何外部的栅格区域。输出四至由系统自动计算。
注:在使用矢量数据作为裁剪依据时,建议输出栅格采用与矢量数据一致的坐标系,以避免空间偏移或裁剪误差。
使用栅格数据
当选择已有栅格数据作为参考时,系统将自动继承其空间与数值参数,用于生成与参考栅格结构一致的输出结果。
自动读取的参数包括:
- 坐标系
- 栅格四至范围
- 像元大小
- 栅格行列数
- 文件格式
- 像元数据类型
- NoData 值
- 压缩类型
该模式适用于需要与现有栅格在空间结构和数值规则上完全一致的分析场景。
捕捉到栅格(Snap Raster)
“捕捉到栅格”用于强制输出栅格与指定参考栅格在网格结构上完全对齐。
启用该选项后,输出栅格将与参考栅格共享相同的网格原点、像元边界和像元中心位置。即使两个栅格具有相同的像元大小,若其网格原点不同,仍可能产生半像元偏移,从而无法进行逐像元计算。捕捉到栅格可避免此类空间错位问题。
启用捕捉到栅格后的约束规则:
- 像元大小
- 栅格行列数
- 输出四至范围
- 有效值范围
均不可手动修改,且必须与参考栅格保持完全一致。
空间参考(Coordinate System)
定义输出栅格所使用的空间参考。
- 默认情况下,输出栅格采用主要输入栅格的坐标系。
- 可显式指定输出坐标系,工具将在输出阶段对结果进行重投影。
四至(Extent)
定义输出栅格在空间上的覆盖范围。
- 默认输出范围为第一个输入数据范围的四至。
- 可通过指定范围或参考数据集限制输出范围。
- 位于输出范围内但无有效输入数据的区域将被赋值为 NoData。
- 具有
对齐四至选项,选中时,会强制栅格数据Extent 对齐到输入的四至,此时会稍微调整像元大小。
像元大小( Cell Size)
像元大小(Pixel Size / Cell Size / Spatial Resolution)用于描述单个栅格像元在真实地理空间中所代表的实际范围,也称为空间分辨率。
定义输出栅格中像元的空间分辨率。昕图会显示像元大小的单位,以当前坐标系进行实现,在地理坐标系下显示为 度/deg ,在投影坐标系下显示为 米/m 。
- 输出栅格仅支持单一像元大小。
- 当输入栅格分辨率不一致时,系统将根据该设置对第一个输入数据进行重采样。
- 像元大小直接影响输出精度与计算性能。
示例:
- 像元大小为 30 m × 30 m,表示每个像元对应地面上 30 米见方的区域
- 栅格空间分辨率为 0.00025°
栅格大小( Raster Size)
栅格大小(Raster Size / Raster Dimensions)用于描述栅格数据在行、列方向上的像元数量,即栅格网格的整体尺寸。
在实现层面,栅格数据可被视为一个二维数组,其大小通常以 行数 × 列数(Rows × Columns) 的形式表示,反映了该数据在空间上被划分为多少个离散单元。
栅格大小决定了:
- 数据的总体规模
- 存储与计算的内存开销
- 空间分析时的计算复杂度
示例:
- 栅格大小为 5000 × 3000,表示该栅格由 5000 行、3000 列像元构成
- 栅格总像元数为 15,000,000
输出文件设置
输出文件路径和名称(Output File Naming)
用于指定输出栅格数据的存储位置及文件名称。
-
输出路径 指定输出栅格文件的保存目录。
-
输出栅格文件 指定输出栅格文件的文件名称。 若未手动指定,工具将自动生成默认文件名,生成规则如下:
[主要输入文件名称]_[工具英文名称]_[任务编号]例如,对输入文件
降雨量.pgv执行插值分析时,生成的输出文件名称为:降雨量_gdal_idw_interpolation_1.tif
该命名规则用于区分不同工具及不同执行任务生成的结果文件,便于批量处理与结果管理。
文件格式
昕图中默认的栅格数据存储格式为GeoTIFF,除了专门的数据格式转换器之外,栅格数据的计算强制设定为GeoTIFF格式。
数据类型(Value Type)
定义输出栅格中像元的数值类型。
- 支持整型和浮点型数据类型。
- 当输入数据类型不一致时,系统自动选择能够容纳所有结果值的数据类型。
- 输出类型应根据分析目的进行选择,以避免精度损失或数据溢出。
| 数据类型 | 数值范围 | 说明 |
|---|---|---|
| 8 位无符号整数 | 0 ~ 255 | 常用于分类栅格或颜色索引值 |
| 8 位有符号整数 | -128 ~ 127 | 支持表示小范围的正负整数 |
| 16 位无符号整数 | 0 ~ 65,535 | 适用于中等数值范围的分类或计数数据 |
| 16 位有符号整数 | -32,768 ~ 32,767 | 可表示中等范围的正负整数值 |
| 32 位无符号整数 | 0 ~ 4,294,967,295 | 适用于大范围计数或索引类数据 |
| 32 位有符号整数 | -2,147,483,648 ~ 2,147,483,647 | 可表示大范围的正负整数值 |
| 单精度浮点数 | 约 7 位有效数字 | 小数,适用于一般连续型分析结果 |
| 双精度浮点数 | 约 15 位有效数字 | 高精度小数,适用于科学计算与精度要求较高的分析 |
NoData 值(NoData Value)
定义输出栅格中用于表示无效或不可计算像元的数值。
- NoData 像元不参与计算过程。
- 当输入数据不足或计算条件不满足时,对应输出像元将被赋值为 NoData。
- 输出 NoData 值可由用户指定。
- NoData 在选择
自动时,默认设置改数值类型的最大值。
数值压缩(Data Compression)
数值压缩用于在不改变栅格空间结构的前提下,降低数据存储体积并优化数据读写效率。在栅格数据中,压缩主要作用于像元数值的存储方式,而不影响像元的位置、分辨率和空间参考。
根据是否保留原始数值信息,栅格压缩方式可分为无损压缩与有损压缩两类。不同压缩方式在文件体积、读写性能、数值精度和适用场景方面存在差异,应根据数据类型和使用目的进行合理选择。
无损压缩(Lossless Compression)
无损压缩在解压后能够完全还原原始像元数值,不会引入任何数值误差,适用于分析、建模及科学计算等对精度要求较高的场景。
无损压缩通常用于:
- 分类栅格与编码类数据
- 连续型分析结果(如插值结果、DEM、模型输出)
- 需要重复计算或长期归档的分析成果
常见无损压缩方式包括 LZW、DEFLATE、LERC、ZSTD 等。其中,部分压缩方式针对浮点型数据进行了专门优化,在保证数值精度的同时显著降低文件体积。
昕图默认使用 LZW 进行压缩。
有损压缩(Lossy Compression)
有损压缩通过牺牲部分数值或影像细节来换取更高的压缩比,解压后的数据无法完全还原为原始数值。该类压缩方式主要面向视觉表达和分发场景,而非精确数值分析。
有损压缩通常用于:
- 遥感影像与卫星影像数据
- 可视化成果与在线发布产品
- 对数值精度要求不高的展示型数据
常见有损压缩方式包括 JPEG、JPEG-XL(有损模式)、WebP 等。
压缩方式选择原则
在选择栅格压缩方式时,应综合考虑以下因素:
- 分析目的:是否需要保持精确的数值一致性
- 数据类型:整数型、浮点型或影像型数据
- 存储需求:磁盘空间与长期归档要求
- 性能需求:数据读取速度与计算效率
一般情况下,分析型数据应优先选择无损压缩;影像展示和发布型数据可根据需求选择合适的有损压缩方式
压缩类型说明
| 压缩类型 | 支持格式 | 压缩方式 | 说明与典型用途 |
|---|---|---|---|
| 无 | GTiff | 无压缩 | 不进行任何压缩,文件体积最大,读写速度最快,适用于临时数据或调试用途 |
| LZW | GTiff | 无损压缩 | 常用的 TIFF 无损压缩方式,兼容性好,压缩率与性能平衡,是多数 GIS 软件的默认选择 |
| LZMA | GTiff | 无损压缩 | 基于 Lempel–Ziv–Markov 算法,压缩比高但压缩和解压速度较慢,适用于对存储空间要求较高的场景 |
| DEFLATE | GTiff | 无损压缩 | 高效的无损压缩算法,广泛用于 GeoTIFF,大幅减小文件体积,适合大规模栅格数据存储 |
| LERC | GTiff | 无损压缩 | 面向浮点型栅格数据优化的压缩算法,适用于高精度连续型数据,如 DEM 或科学计算结果 |
| LERC_DEFLATE | GTiff | 无损压缩 | LERC 与 DEFLATE 的组合方式,在保证无损的前提下进一步提升压缩效率,适合大规模浮点栅格数据 |
| PackBits | GTiff | 无损压缩 | 简单的行程编码方式,压缩效率较低,但实现简单,对小型或规则数据集较为有效 |
| ZSTD | GTiff | 无损压缩 | 新一代无损压缩算法,兼顾高压缩率与高速读写,GDAL 3.x 起支持,适合大规模栅格数据 |
| JPEG | GTiff / 遥感影像 | 有损压缩 | 主要用于遥感影像和卫星图像,压缩效率高,但会引入不可逆的图像失真 |
| JXL | GTiff / 遥感影像 | 有损 / 无损 | JPEG-XL 格式,支持更高压缩比与更优画质,GDAL 3.x 起支持,适合现代影像数据存储 |
| WEBP | GTiff / Web 场景 | 有损 / 无损 | 面向 Web 优化的图像格式,压缩效率高,适用于 Web GIS 或在线发布场景 |
| CCITTRLE | GTiff / 文档影像 | 无损压缩 | 适用于黑白(1-bit)图像,通过行程编码实现压缩,常用于扫描文档 |
| CCITTFAX3 | GTiff / 文档影像 | 有损压缩 | CCITT Group 3 传真压缩,主要用于黑白文档影像,压缩效率高于 RLE |
| CCITTFAX4 | GTiff / 文档影像 | 有损压缩 | CCITT Group 4 传真压缩,比 Group 3 更高效,常用于扫描文档与二值影像 |
矢量保存一般约定
当工具的输出结果为矢量要素数据集时,将遵循统一的矢量保存约定。
输出格式标准
昕图默认推荐使用云原生格式进行存储:
- .pgv (PostGIS Vector):针对大规模要素集优化的在线存储格式,支持极速加载。
- .gpv (GeoPackage Vector):兼顾便携性与高性能的本地单文件数据库格式。
- Shapefile/GeoJSON:仅建议用于与第三方软件进行简单数据交换。
坐标系继承与重投影
- 默认行为:输出要素将继承第一个输入要素的坐标参考系统(CRS)。
- 重投影设置:用户可在“高级设置”中显式指定输出坐标系。若输入与输出坐标系不一致,工具将自动执行实时投影变换。
字段映射规则
- 全量保留:默认情况下,输出要素将继承源数据的所有非系统字段。
- 指定输出字段:在复杂工具(如合并、连接)中,用户可手动勾选需要保留的字段,并配置字段合并规则(如 First, Last, Sum)。
- 自动前缀:当涉及空间连接或叠加分析导致字段冲突时,系统会自动为重名字段添加
LEFT_或RIGHT_前缀。
任务与命名
- 自动命名:遵循
[源文件名]_[工具ID]_[序号]的规则。 - 异步处理:所有计算任务均在后端异步执行,用户可在“任务列表”中实时监控进度并在完成后一键定位至结果。